
Wie man die Konsistenz echter Datensätze überprüft
April 2020: Emmanuel Bert beschreibt, wie unser Real Data Set Consistency Checker Ihnen bei Kalibrierungs- und Validierungsaufgaben helfen kann.


Das RDS-Modul in Aimsun Next akzeptiert die meisten der bekannten Datentypen, die für ein Simulationsmodell verwendet werden. Ein RDS-Lesemodul kann einfach konfiguriert werden, um Daten aus textbasierten Dateien oder Positionsdaten in einem GPS-basierten Standardformat abzurufen. Weitere Details zum RDS-Leser im Benutzerhandbuch.
Manchmal können RDS eine große Menge an Daten enthalten. Um Zeit beim Abrufen und Analysieren zu sparen, kann man nach Teilnetzen oder nach Zeit gefiltert werden. In einem Testmodell wurden zum Beispiel zwei Datenquellen verwendet: Autobahndaten und Daten von signalisierten Kreuzungen. Sie wurden im RDS wie in Abbildung 1 dargestellt kombiniert. Der ursprüngliche Datensatz wurde 24 Stunden lang in Abständen von 15 Minuten aufgezeichnet. Bei der Analyse eines bestimmten Modellzeitraums, z. B. der Nachmittagsspitze, muss man nicht den gesamten Datensatz verwenden. Man kann ein Zeitfilter angewendet werden, um Informationen aus dem gewünschten Zeitintervall (z. B. 14 bis 19 Uhr) abzurufen. Ein Beispiel für die abgerufenen Daten für den gesamten Tag im Vergleich zur Nachmittagsspitze ist in Abbildung 2 dargestellt.
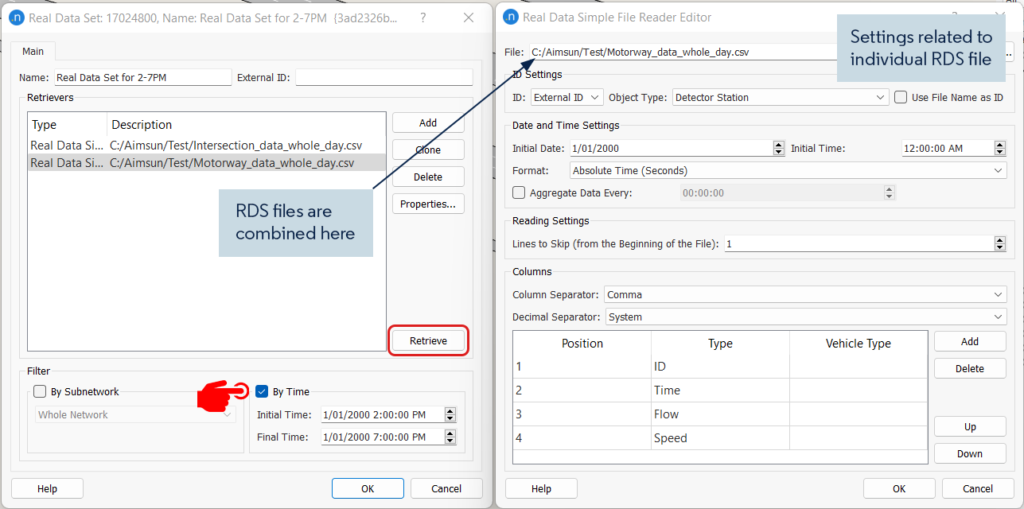
Abbildung 1: Ein Beispiel für das RDS-Eingabefenster
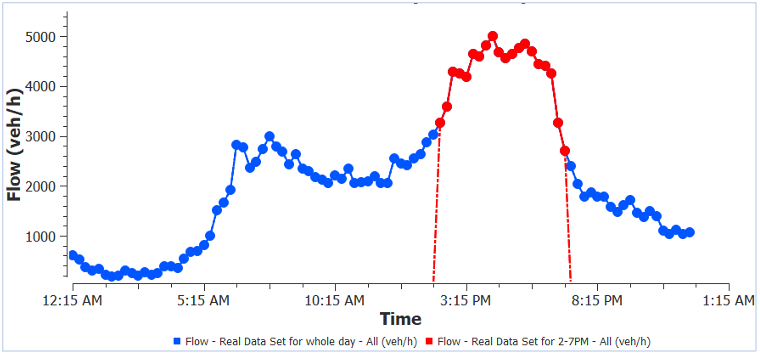
Abbildung 2: Ein Beispiel für einen Detektorfluss mit Daten für den ganzen Tag im Vergleich zu den Spitzenwerten am Abend
Während des Datenabrufs wird eine Reihe von Standardprüfungen durchgeführt. Dazu gehören ungültiges Datum/Uhrzeit, Anfangszeit und Intervall, ungültige oder fehlende Datenwerte, negative und NaN-Datenwerte, fehlende Objekte im Modell gemäß der RDS-ID-Einstellung und IDs mit mehreren Objekten im Modell. Auch die Werte für Zeit, Objekt und Fahrzeugtyp werden in jedem gescannten Datensatz überprüft. Alle in den Daten gefundenen Anomalien werden gemeldet, und im Protokollfenster wird für jede gescannte Datei eine Erfolgs-/Fehlermeldung des Abrufvorgangs gedruckt. Ein Beispiel für das Abfrageergebnis für das zuvor berichtete Test-RDS ist in Abbildung 3 unten dargestellt.
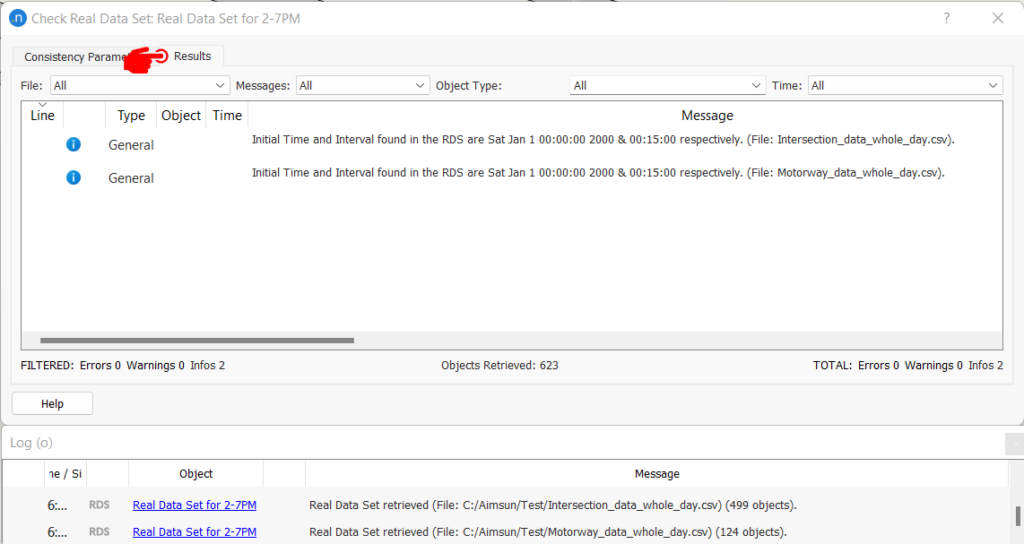
Abbildung 3: Registerkarte RDS-Abfrageergebnisse (oben) und Protokollfenster (unten)
Das Realdatensätze-Werkzeug stellt sicher, dass die Daten mit den Durchfluss-, Geschwindigkeits- und Belegungswerten übereinstimmen. Der Standardausblick des Konsistenzprüfers ist in Abbildung 4 dargestellt. Die Standardwerte sind nur ein Richtwert. Weitere Informationen über die Wahl der Parameterwerte findet man später.
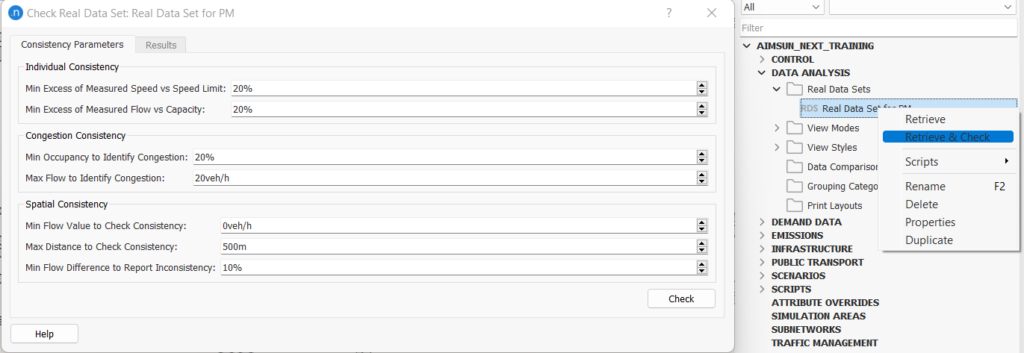
Abbildung 4: RDS-Konsistenzprüfung mit Standardwerten
Minimale Überschreitung der gemessenen Geschwindigkeit gegenüber der Geschwindigkeitsbegrenzung: Identifiziert jeden einzelnen Datenpunkt, bei dem der RDS-Geschwindigkeitswert 20 % höher ist als die im Modell kodierte Geschwindigkeitsbegrenzung für den Abschnitt (oder die Abzweigung). Das Fahrerverhalten, die Lage des Untersuchungsgebiets und der Zeitpunkt der Analyse (Hauptverkehrszeit, Nebenverkehrszeit) können diese Auswahl beeinflussen. Eine kurze Zusammenfassung der Daten kann einen besseren Einblick in diesen Schwellenwert geben. Das Hauptaugenmerk sollte auf der Identifizierung von Ausreißern und Dateneingabefehlern liegen. So kann beispielsweise in einem Straßenabschnitt mit einer Geschwindigkeitsbegrenzung von 100 km/h eine Geschwindigkeitsangabe von 300 km/h ein Dateneingabefehler sein, während 150 km/h ein Ausreißer sein können oder auch nicht.
Min. Überschreitung des gemessenen Durchflusses gegenüber der Kapazität: Identifiziert jeden einzelnen Datenpunkt, bei dem der RDS-Durchflusswert 20 % höher ist als die im Modell kodierte Kapazität des Abschnitts (oder der Abzweigung). Wenn die Daten nach Fahrspur abgerufen werden (z. B. Fahrspurdetektor), werden sie mit der Fahrspurkapazität verglichen.
Stau-Konsistenz: Ein Datenpunkt wird als überlastet identifiziert, wenn seine Belegung hoch und sein Durchfluss niedrig ist; die Schwellenwerte für eine hohe Belegung und einen niedrigen Durchfluss werden durch die Mindestbelegung zur Identifizierung von Staus und den maximalen Durchfluss zur Identifizierung von Staus definiert. Im Falle von mehrspurigen Objekten (Abschnitte oder Detektorstationen) verwendet der Standardaggregationsprozess den Durchflusswert als Summe der verfügbaren Fahrbahndurchflüsse, während die Belegung über die verfügbaren Fahrbahnbelegungen gemittelt wird. Daher muss man einen höheren Wert für den Durchfluss wählen, um eine Überlastung zu erkennen, wenn es Detektoren gibt, die mehrere Fahrspuren abdecken.
Räumliche Konsistenz: Es kann die Inkonsistenz des Verkehrsflusses (oder der Zählung) zwischen zwei gemessenen Punkten innerhalb einer bestimmten Entfernung feststellen. Er kann auch Inkonsistenzen zwischen eingehenden und ausgehenden Flüssen in einem Knoten erkennen. Der Algorithmus benötigt drei Parameter:
Hinweise zur Prüfung der räumlichen Konsistenz
Wenn der Datensatz einem Teilwert entspricht (der nicht alle Fahrspuren des Abschnitts abdeckt), werden die Daten zu den fehlenden Fahrspuren innerhalb von 50 m gesucht. Wird dieser Datensatz nicht gefunden, wird er nicht auf räumliche Konsistenz geprüft.
Der mögliche Unterschied im Durchfluss aufgrund der Entfernung zwischen den Messpunkten wird berücksichtigt, indem eine ungefähre Speicherkapazität berechnet wird, wenn alle Fahrzeuge zwischen diesen beiden Punkten angehalten würden. Wenn es keine geometrischen Störungen zwischen zwei Punkten gibt (d. h. keine Zusammenführung/Abzweigung oder Schwerpunktverbindungen), aber die Durchflussdifferenz abzüglich der Speicherkapazität zwischen beiden Punkten die Mindestdurchflussdifferenz für die Meldung einer Inkonsistenz überschreitet, wird ein Fehler ausgegeben, da eine der Beobachtungen theoretisch falsch sein sollte.
Bei der Einzel- und Staukonsistenzprüfung betrachtet die RDS-Konsistenzprüfung jede Beobachtung zu jedem Zeitpunkt und wendet den Algorithmus an. Bei der räumlichen Konsistenzprüfung werden mehrere Objekte innerhalb jedes Zeitraums betrachtet. Wenn der Datensatz in kleinen Zeitintervallen (z. B. 15 Minuten) gespeichert wird, könnte eine große Liste von Warnungen erzeugt werden, die überwältigend und manchmal schwierig zu handhaben sein könnte. Bei dem oben erwähnten Testmodell war der Datensatz beispielsweise 24 Stunden lang, mit Intervallen von 15 Minuten. Um die Laufzeit zu verkürzen, kann der Datensatz mit den oben beschriebenen Filteroptionen auf 5 Stunden (14 – 19 Uhr), den Analysezeitraum, gekürzt werden. Die Konsistenzprüfung mit dem Standardwert ergab insgesamt 849 Meldungen. Die Filteroption würde helfen, die Ausgabe nach Meldungstypen, Objekttyp (z. B. Abschnitt, Knoten, Detektoren) und nach RDS-Datei zu trennen.
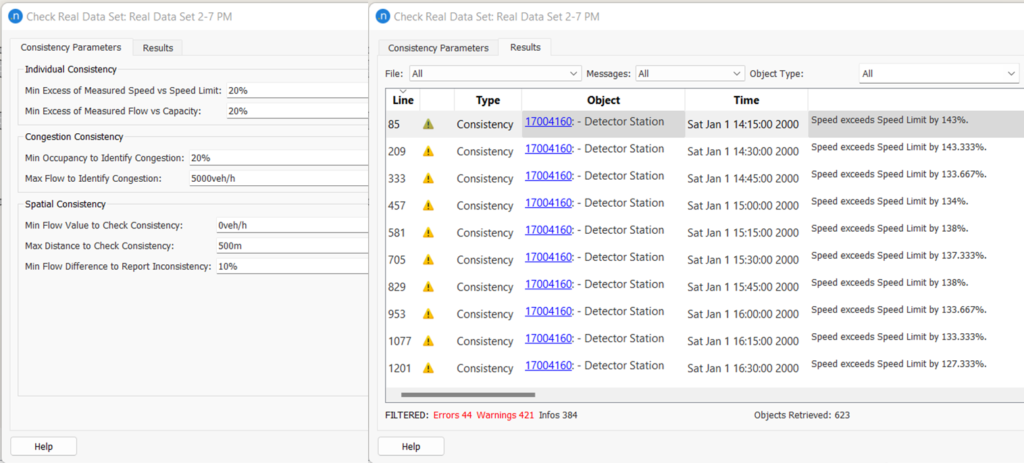 Abbildung 5: Beispiel für RDS-Konsistenzprüfungsmeldungen
Abbildung 5: Beispiel für RDS-Konsistenzprüfungsmeldungen
Wenn man uns Abbildung 5 genau ansieht, wird für dieselbe Detektorstation für jeden Zeitpunkt dieselbe Fehlermeldung erzeugt. Je nach Anwendung der Daten muss man sich jedes Zeitintervall ansehen, und manchmal sind aggregierte Daten über einen bestimmten Zeitraum angebracht. In den folgenden Abschnitten werden einige gängige Anwendungen dieses Instruments erörtert.
Der statische OD-Anpassungsprozess betrachtet das simulierte Volumen und vergleicht es mit dem RDS-Volumen. Die Daten müssen nicht zeitabhängig sein. Wir sind vor allem an der Inkonsistenz der Durchflüsse interessiert, da sie sich negativ auf den Anpassungsprozess auswirken könnte. Wir können die Daten nach dem Simulationszeitraum aggregieren. Im Testmodell haben wir beispielsweise die im RDS-Reader verfügbare automatische Aggregationsoption genutzt, wie in Abbildung 6 dargestellt.
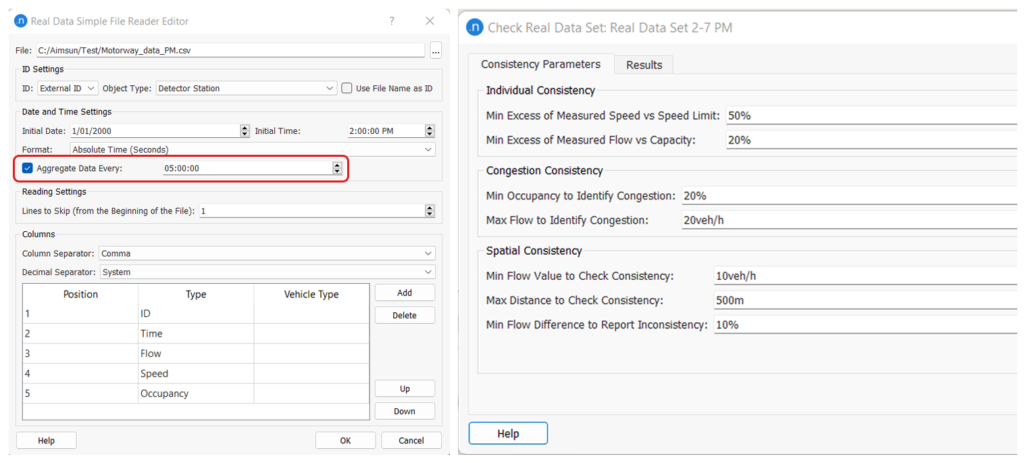
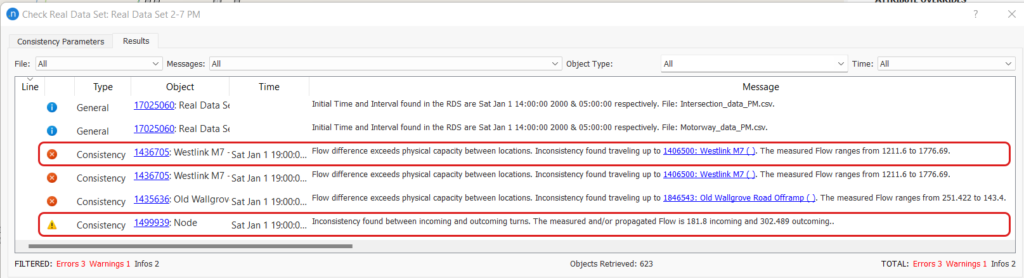
Abbildung 6: RDS-Konsistenzprüfung mit aggregierten Daten
Wenn die Konsistenzprüfung auf den aggregierten Daten durchgeführt wird,ist die Anzahl der räumlichen Konsistenzfehler von 44 auf 3 gesunken. Wenn man nicht an Geschwindigkeitswerten interessiert ist, kann ein hoher Schwellenwert für die gemessene Geschwindigkeit gegenüber dem Tempolimit verwendet werden, um Berichte über Geschwindigkeitsfehler zu vermeiden. In ähnlicher Weise können auch die Belegungsprüfungen mit einem niedrigen Wert für den maximalen Verkehrsfluss zur Erkennung von Staus vermieden werden.
In der Beschreibung des ersten Fehlers heißt es, dass die beiden Abschnittsdetektoren einen Durchflussunterschied von 565 (1776-1211) Fahrzeugen aufweisen. Da es keine anderen Geometriestörungen gibt, muss einer der Durchflusswerte falsch sein. In diesem Fall wurde der niedrigere Durchflusswert durch einen fehlerhaften Detektor verursacht. In der letzten Warnmeldung basiert die Berechnung für den Knoten auf dem ein- und ausgehenden Durchfluss, wie in Abbildung 7 dargestellt. Interessanterweise fehlten die Daten für eine Abflusskurve, die durch die Informationen des nachgelagerten Knotens neu berechnet wurde.
Die manuelle Identifizierung solcher Inkonsistenzen in den Daten würde viel Zeit in Anspruch nehmen. Die RDS-Konsistenzprüfung hingegen erfolgt größtenteils automatisch und läuft innerhalb von Sekunden ab, um nützliche Informationen über Flussschwankungen zu liefern. Man sollte den Inkonsistenzdetektor für den Prozess der statischen OD-Anpassung aktualisieren/vermeiden.
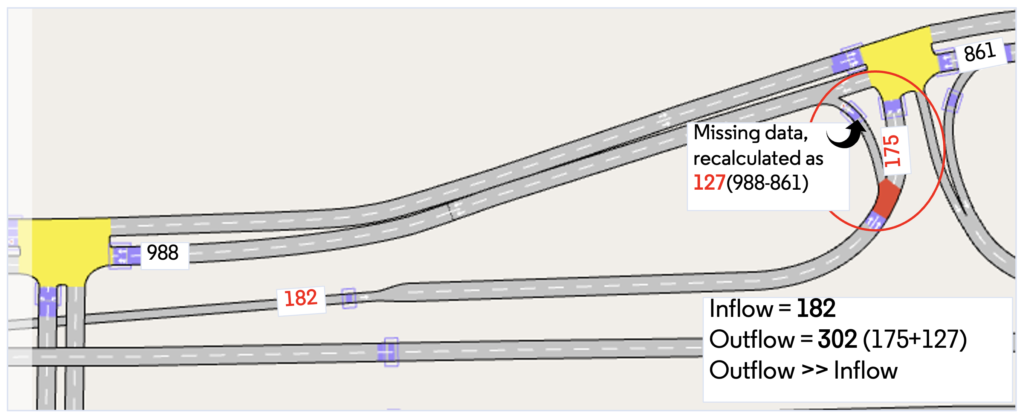
Abbildung 7: Berechnung des Durchflusses für die Knoteninkonsistenzprüfung (die Zahlen geben den durchschnittlichen Durchfluss an)
Geschwindigkeitsdaten sind wichtig für die Modellkalibrierung und -validierung. Bei diesem Prozess werden Geschwindigkeitsanomalien durch den Vergleich mit der Höchstgeschwindigkeit im Abschnitt (oder in der Kurve) ermittelt. Geschwindigkeitsdaten sind zeitabhängig und sollten für jeden einzelnen Zeitpunkt analysiert werden oder können nach dem Zeitintervall der Modellberichterstattung zusammengefasst werden. Manchmal kann diese Analyse auch helfen, Anomalien bei der Geschwindigkeitsbegrenzung im Abschnitt zu erkennen. Wenn beispielsweise die Geschwindigkeitsbegrenzungsdaten für das Modell veraltet sind, kann das neueste RDS mögliche Stellen identifizieren, an denen Änderungen erforderlich sind. In diesem Testmodell werden häufig Warnungen für die Rampengeschwindigkeit gemeldet. Ein Beispiel ist in Abbildung 8 zu sehen, wo die Rampengeschwindigkeit auf 60 km/h und die Autobahngeschwindigkeit auf 110 km/h eingestellt war. Die Rampengeschwindigkeit an der ermittelten Stelle ist möglicherweise nicht gerechtfertigt, da der Fahrer gerade erst nach der Ausfahrt von der Autobahn mit dem Abbremsen begonnen hatte. Die Rampengeschwindigkeit kann auf der Grundlage des RDS-Geschwindigkeitswerts aktualisiert werden.
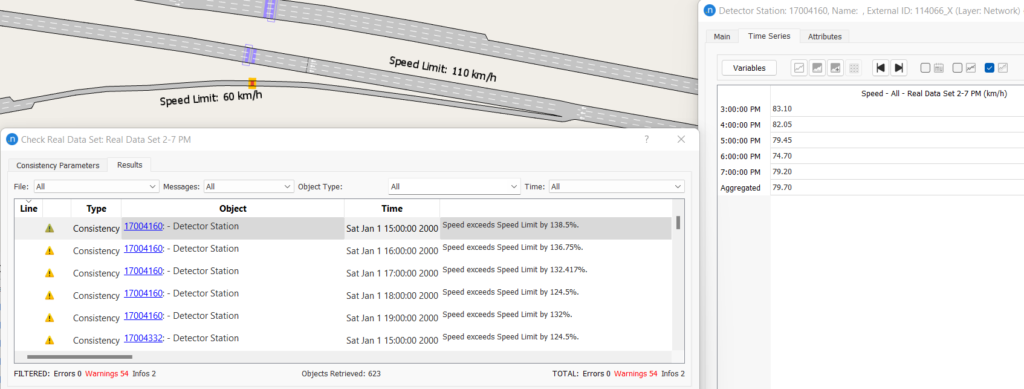
Abbildung 8: Identifizierung von Anomalien der Geschwindigkeitsbegrenzung auf Abschnitten anhand von RDS
Anhand der Verkehrsfluss- und Belegungsdaten können die überlasteten Orte aus dem RDS ermittelt werden. Dieses Ergebnis wird als Information gekennzeichnet. Die identifizierten Orte können zur Erstellung von Abschnittsgruppierungen mit Staus verwendet werden, um den Prozess der statischen OD-Anpassung zu unterstützen. Sie helfen auch bei der Modellvalidierung, da sie über typische reale Orte informieren, an denen es zu Staus kam. Im Testmodell haben wir die 1-Stunden-Aggregation verwendet, um die Staukonsistenz zu ermitteln. Die Wahl der Parameter sollte auf den Verkehrsfluss- und Belegungswerten beruhen, die an einigen typischen überlasteten Orten beobachtet wurden. In Abbildung 9 ist das Verkehrsfluss- und Belegungsprofil zweier typischer überlasteter Stellen (morgens und abends) auf der Autobahn dargestellt. Auf der Grundlage dieses Profils wird der Parameterwert für den maximalen Verkehrsfluss zur Erkennung von Staus auf 4200 Fahrzeuge pro Stunde und die Mindestbelegung zur Erkennung von Staus auf 25 % festgelegt. Ein niedrigerer Wert für die Mindestauslastung könnte zu einer Vielzahl von Fällen mit leichten Staus oder Abschnitten mit hoher Auslastung führen. Ein Beispiel für die Ergebnisse der Staukonsistenz ist in Abbildung 9 mit den verwendeten Parameterwerten dargestellt. Es zeigt zum Beispiel, dass der Detektor 4421 während des Nachmittags teilweise überlastet war.
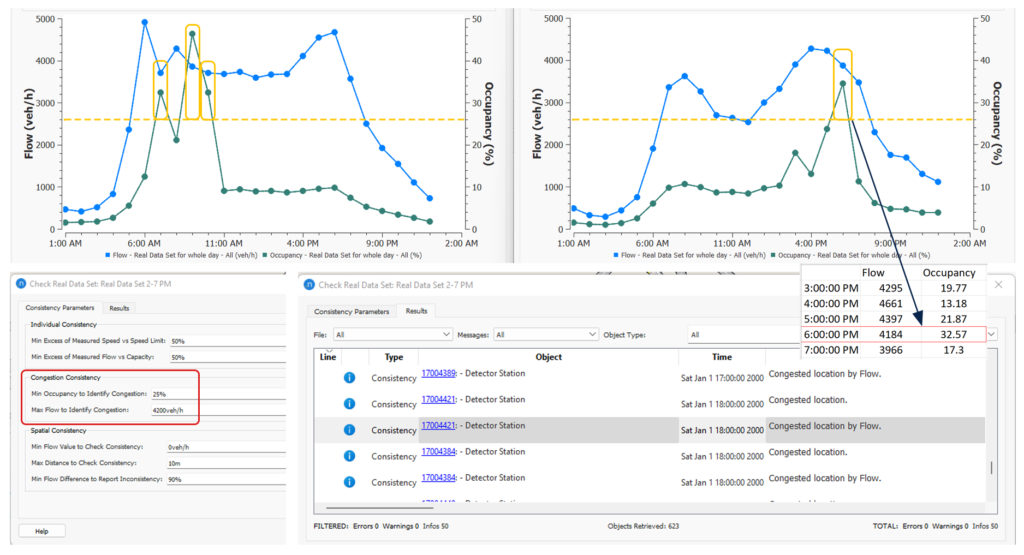
Abbildung 9: Ein Beispiel für den Aufbau und die Ergebnisse der Staukonsistenz
April 2020: Emmanuel Bert beschreibt, wie unser Real Data Set Consistency Checker Ihnen bei Kalibrierungs- und Validierungsaufgaben helfen kann.
Oktober 2016: Tamara Djukic erklärt, wie das Tool Gruppierungskategorie die Anwendung von Verkehrsdaten zur Kalibrierung und Validierung von Verkehrsmodellen oder zur Verarbeitung von Simulationseingangs- und -ausgangsdaten beschleunigen und verbessern kann. Mit zusätzlicher Unterstützung von Timothy Lim und Phoebe Ho.
