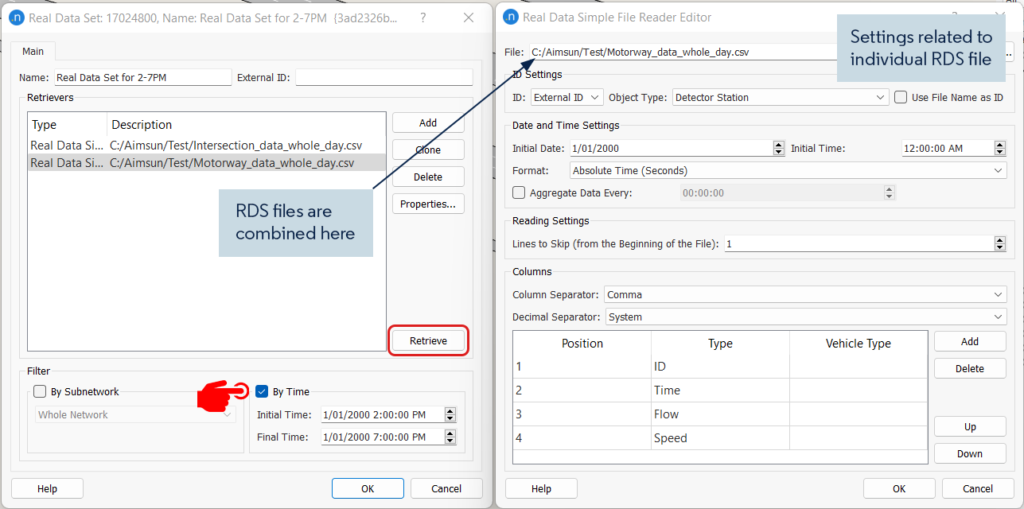
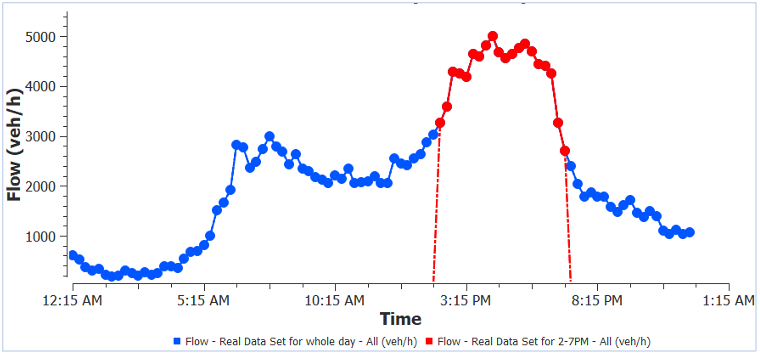
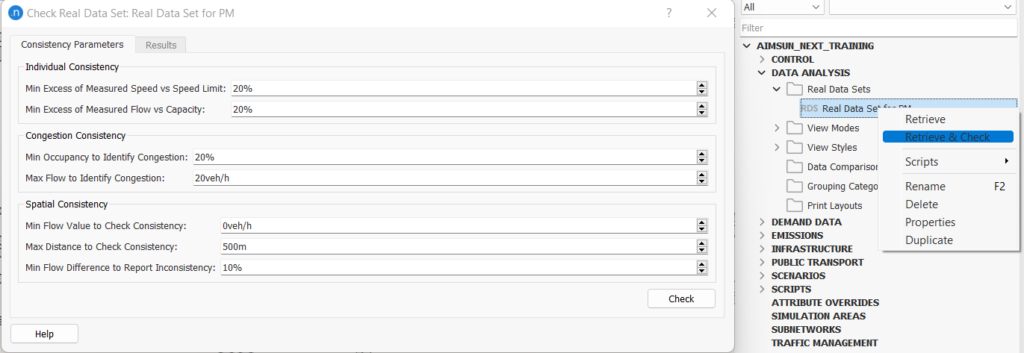
3. Application of RDS Consistency Check
For individual and congestion consistency check, the RDS consistency check looks at each observation at each time point and applies the algorithm. For spatial consistency check, it looks at multiple objects within each time period. When the dataset is stored at small time intervals (e.g.,15min) it could generate a big list of warnings which could be overwhelming and sometimes difficult to manage. For example, in the test model mentioned before, the dataset was 24 hours in duration with 15min intervals. To reduce runtime the dataset can be trimmed to 5hrs (2-7 pm), which is the analysis period, using the filter options described above. The consistency check with the default value generated 849 messages in total. The filter option would help to separate the output by message types, object type (e.g. section, node, detectors), and by RDS file.
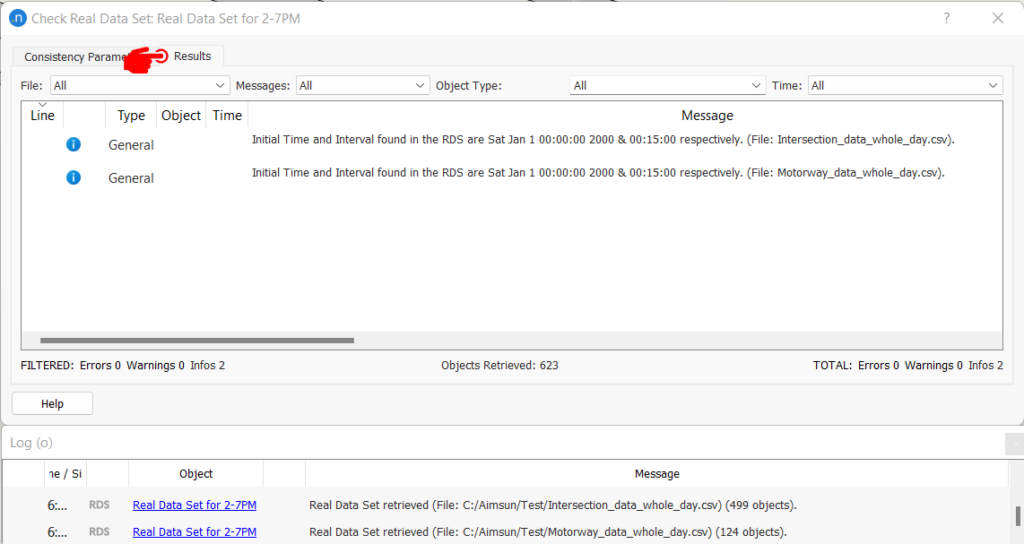
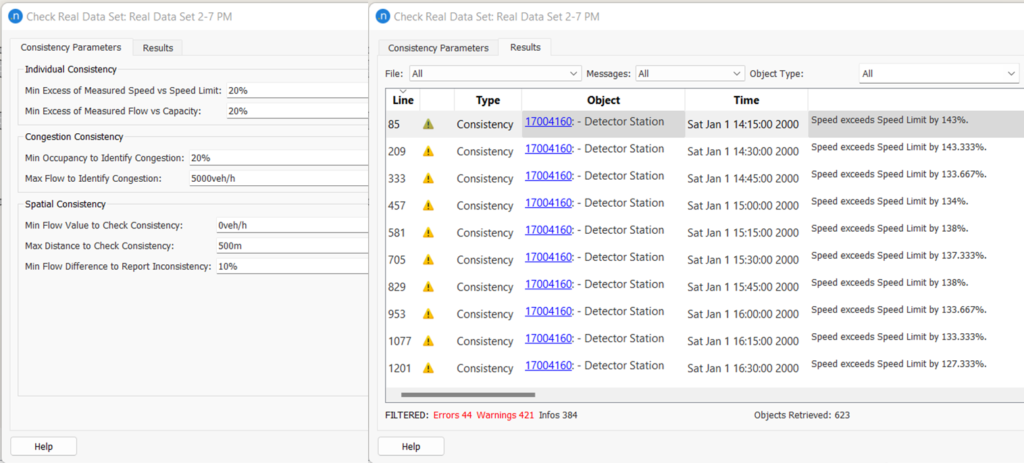 Figure 5: Example of RDS consistency check messages
Figure 5: Example of RDS consistency check messages
If we look closely at Figure 5, for the same detector station same error message is generated for each time point. Depending on the application of the data we may need to look at each time interval and sometimes aggregated data over a period would be appropriate. In the following sections, some common applications of this tool are discussed.
3.1 Static OD adjustment:
The static OD adjustment process looks at the simulated volume and compares that with the RDS volume. The data does not need to be time dependent. We are mostly interested in flow inconsistency as it could negatively impact the adjustment process. We can aggregate data by the simulation period. For example, in the test model, we have utilized the automatic aggregation option available in the RDS reader as shown in Figure 6.
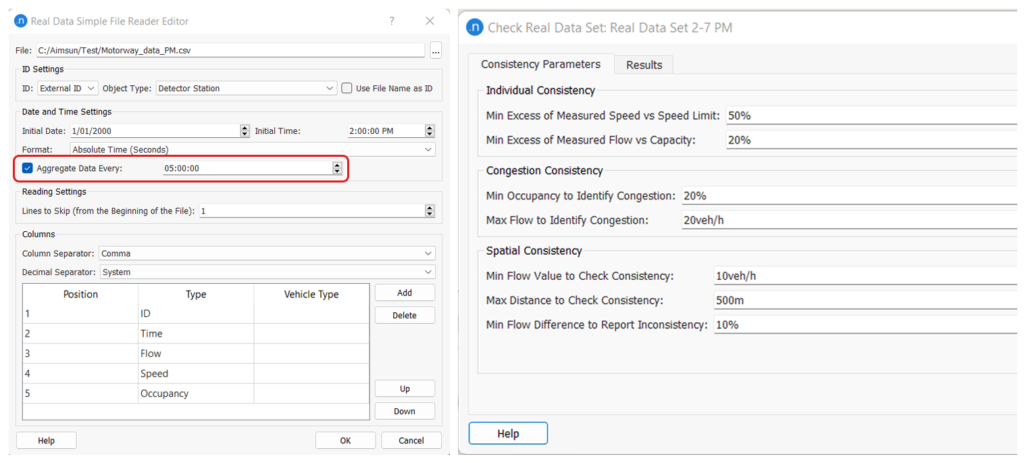
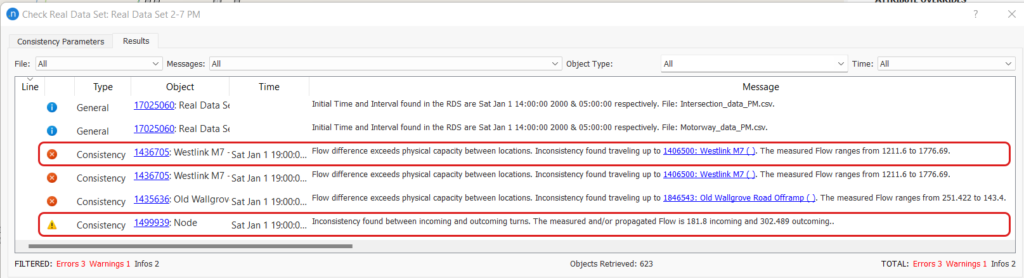
Figure 6: RDS consistency check with aggregated data
When the consistency check is performed on the aggregated data, the number of spatial consistency errors has dropped from 44 to 3. When we are not interested in speed values, a high threshold for Measured Speed vs Speed Limit can be used to avoid reports on speed errors. Similarly, the occupancy checks can also be avoided with a low value for Max Flow to Identify Congestion.
If we look at the description of the first error, it says that the two section detectors have a flow difference of 565 (1776-1211) vehicles. As there are no other geometry interferences one of the flow values must be incorrect. In this case, the lower flow value was caused by a faulty detector. In the last warning message, the calculation for the node is based on incoming and outgoing flow as shown in Figure 7. Interestingly, data for one outflow turn was missing which was recalculated by the downstream node information.
Manually identifying such inconsistency within the data would take a long time. Whereas the RDS consistency check is mostly automatic and runs within seconds to provide useful information about flow variation. We should update/avoid the inconsistent detector for the Static OD adjustment process.
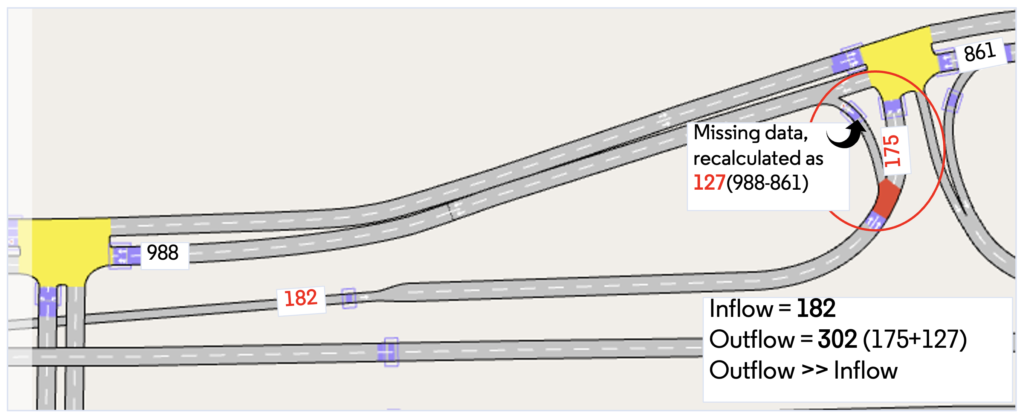
Figure 7: Calculation of flow for node inconsistency check (the numbers denote average flow)
3.2 Speed refinement:
Speed data are important for model calibration and validation. The process identifies speed anomalies by comparing them with the section (or turn) speed limit. Speed data is time-dependent and should be analyzed by each time point or can be aggregated by the model reporting time interval. Sometimes this analysis can also help us to identify anomalies in section speed limit. For example, if the speed limit data for the model is outdated, the latest RDS can identify possible locations where changes are required. In this test model, warnings for the ramp speed are frequently reported. One example is shown in Figure 8 where the ramp speed limit was set to 60 km/hr and the motorway speed limit was 110 km/hr. The ramp speed at the detected location may not be justified as the driver would have just started to slow down after exiting the motorway. The ramp speed may be updated based on the RDS speed value.
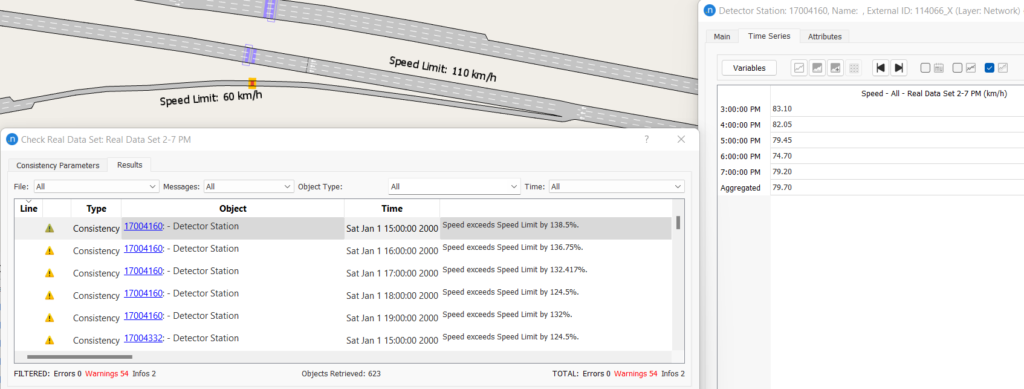
Figure 8: Identifying section speed limit anomalies from RDS
3.3 Congested sections:
With flow and occupancy data, the congested locations can be identified from the RDS. This result is marked as information. The identified locations can be used to create congested section grouping to assist the Static OD adjustment process. It will also help the model validation process as it informs typical real-life locations where the congestion occurred. In the test model, we have used 1-hour aggregation to report congestion consistency. The parameter choice should be based on the flow and occupancy value observed in some typical congested locations. In Figure 9 the flow and occupancy profile of two typical congested locations (AM and PM) on the motorway is shown. Based on this profile, the parameter value for Max Flow to Identify Congestion is set to 4200 vehicles per hour and Min Occupancy to Identify Congestion is set to 25%. A lower value for min occupancy could produce a lot of cases with mild congestion or sections at capacity. An example of the Congestion consistency outputs is shown in Figure 9 with parameter values used. It identifies, for example, that the detector 4421 was partially congested during the PM period.
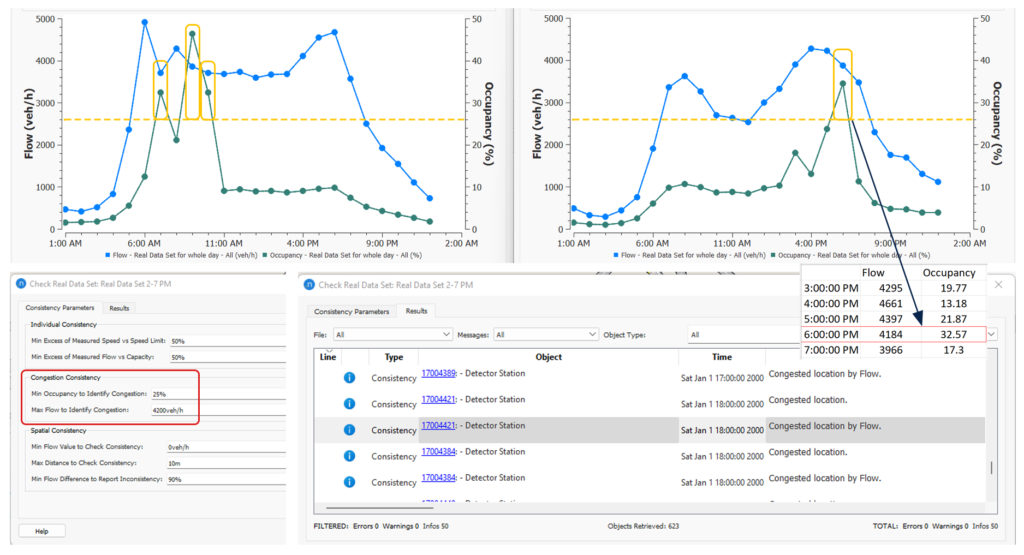
Figure 9: An example of congestion consistency setup and results