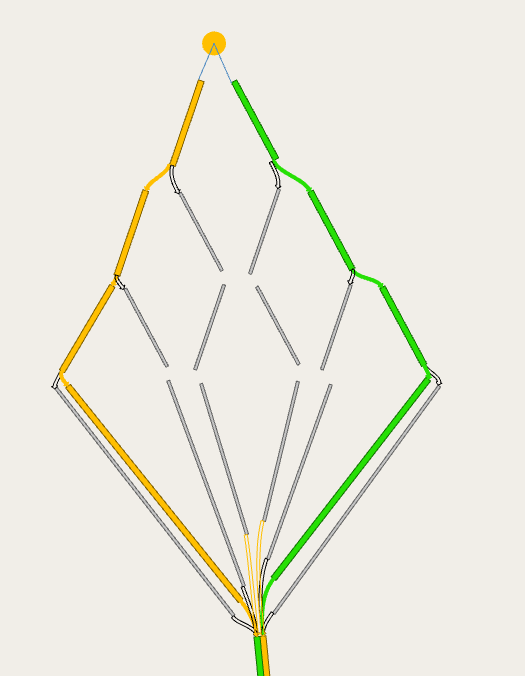
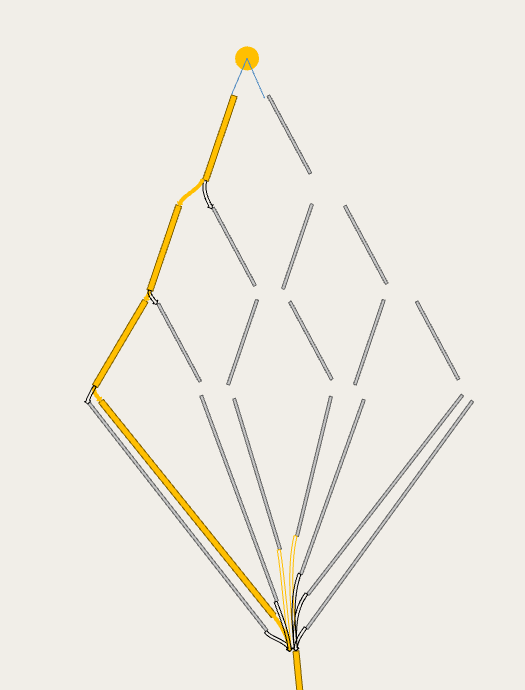
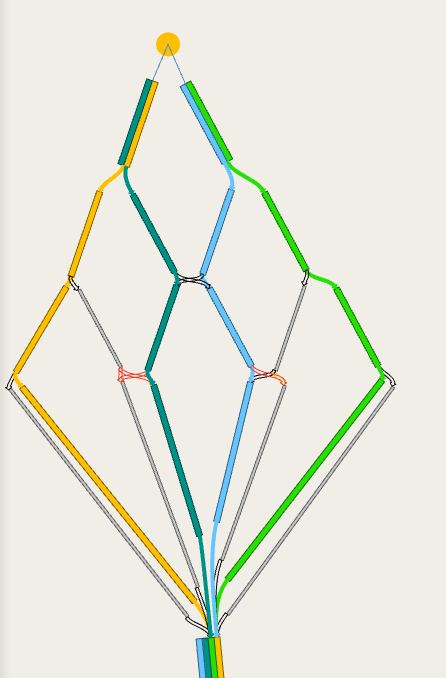
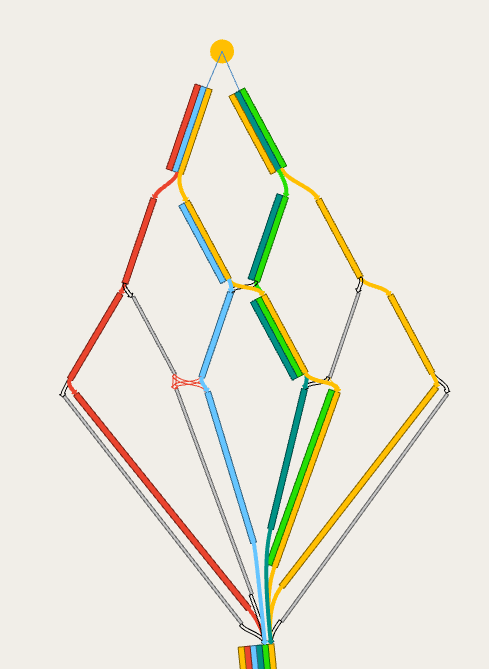
Dynamic assignments
For dynamic experiments (macro-meso, meso-micro, meso and micro) connections have no cost, but there are several parameters that control how each vehicle chooses between multiple entrance and exit connections and how the paths between them are calculated and evaluated
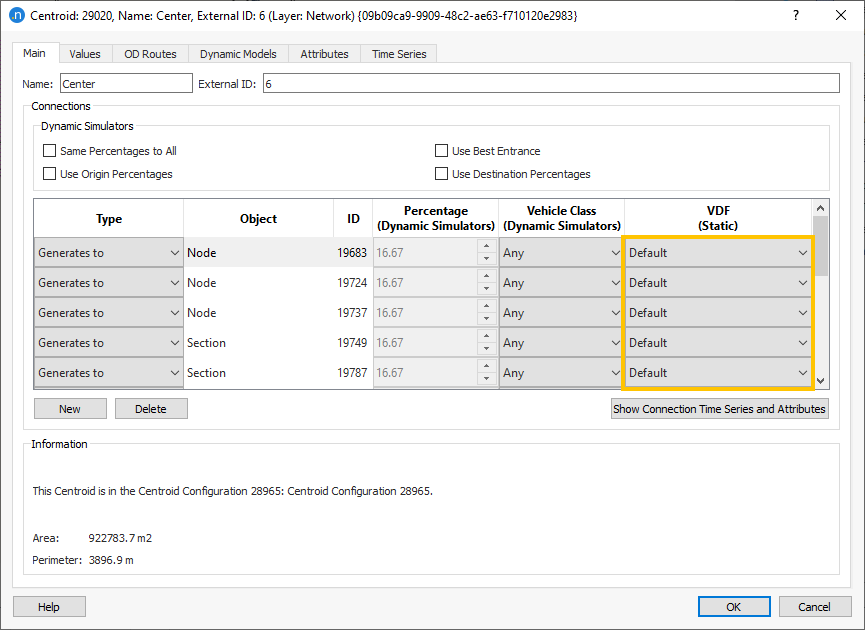
These are defined in the centroid properties:
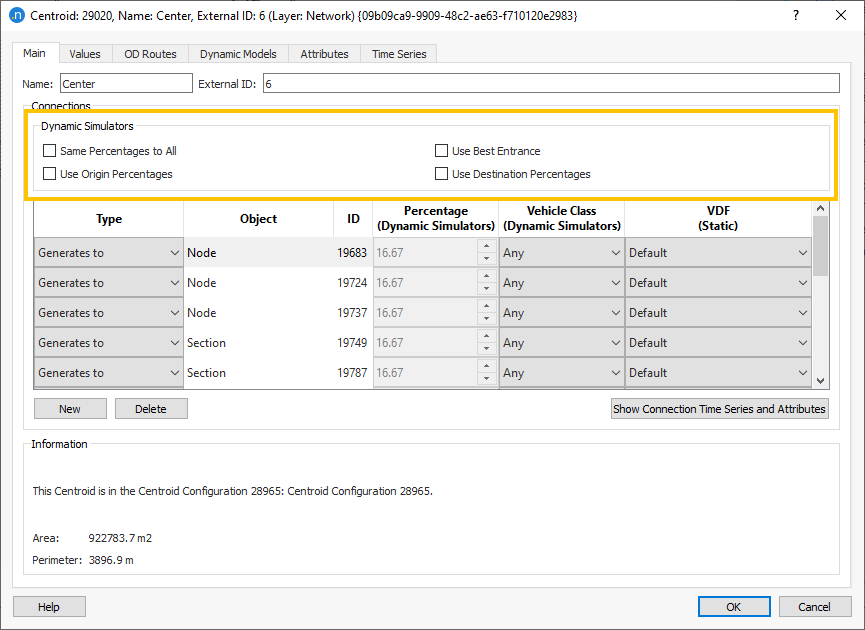
If no box is ticked, then the vehicles choose a connection according to the cost to their destination, as calculated using the initial and dynamic cost functions. In general, this means that vehicles use the entrance(s) that will get them to their destination quickest, and therefore this should be the default and preferred setting.
For dynamic user equilibrium (DUE), when using Dijkstra, at the end of each departure interval and each iteration, a new path tree is calculated but only one path, the one with the least cost, is added to the path list, even if the origin centroid has multiple connections. When using A-star just one point-to-point path is calculated. The path is added to the path set up to the maximum number of paths set in the dynamic traffic assignment tab, and the vehicles are distributed between them according to the proportions calculated by the MSA, WMSA or gradient-based algorithm.
Therefore, if split percentages are not manually set, the assignment ultimately determines the split of the trips between the different entrance and exit connections: in the case of SRC, the discrete choice model applied to the cost of the different options; in the case of DUE, the MSA, WMSA or gradient-based algorithm.
On the other end, if you set entrance or exit connection percentages (or both) each connection is considered as a separate origin or/and destination both in the path calculation and evaluation, and in the computation of convergence measures.
If you use destination percentages, you are first splitting the demand between the exit connections with the given proportions, then the path calculation will assign the vehicles from their origin to their respective destination connection. Therefore, if you use destination percentages, you are forcing the path finding process to calculate one path tree for each exit connection, which increases the runtime and memory consumption as if you had as many destination centroids as exit connections.
If you use origin percentages, you are first splitting the demand between the entrance connections with the given proportions, then the path calculation will assign the vehicles from their respective origin connection to their destination.
Same percentages to all has the same effect as using both origin and destination percentages, while setting for each a value equal to 100% divided by the number of entrance and exit connections respectively.
When you use percentages, the max number of paths is applied to each origin connection-destination centroid (if using only origin percentages), to each origin centroid-destination connection (if using only destination percentages) or to each origin connection-destination connection (if using both); therefore, the max number of paths between an OD pair becomes the total combination of possible entrance/exits multiplied by the max number of paths parameter.
Note that the percentages you set are applied homogenously to all vehicles that have that origin (regardless of their destination – provided there is feasible path) or destination (regardless of the origin – provided there is a feasible path) and therefore vehicles may be assigned to an entrance or exit that doesn’t allow them to get quicker to their destination.
For this reason, you should not use percentages just as a way to spread traffic, or to obtain an observed count on the entrances/exits; they should only be used in specific situations, generally when the reason to pick one or another connection is not related to the convenience of the path, i.e. when you want to obtain the same result of splitting a centroid into multiple centroids (as with the
split/join feature included in Aimsun Next 22), but without modifying the network. It is advised that if you have known percentage splits, that you split your centroids as it can be beneficial when calibrating and validating the model, particularly in adjustment.