Towards ML-assisted traffic simulation

Ferran Torrent
Senior Data Scientist at Aimsun
Traffic simulation systems are highly complex and require huge computational effort, especially for large-scale models where dynamic simulation represents the evolution of congestion over time. The Aimsun team is always mindful of this challenge and actively seeks ways to reduce the computational effort for our own real-time traffic simulation system, Aimsun Live, particularly for super large-scale networks.
Machine Learning (ML) is sometimes posed as an alternative to simulation-based approaches. ML models are efficient to build from data, and once built, provide predictions from input data. Offering real-time traffic predictions is not a challenge, especially when the throughput time is down to one minute. However, ML models present serious difficulties when they must provide predictions for a target variable that is not observed, or in situations not represented in the training dataset. That’s because ML models seek correlations (linear or non-linear relationships) between explanatory and target variables and not causality. Causal inference or causal modelling may solve this challenge and the literature exhibits some approaches that make use of causal inference theory and graph-based modelling for timeseries forecasting. However, for normal levels of traffic observability, which, even in the best cases, only cover a small portion of the network, causal inference is currently unfeasible.
On the other hand, traffic simulation systems require a great effort in modelling traffic demand and network so that they can provide causal inference of what will happen, depending on the estimated demand and the state of supply, even in locations with no observability. However, modelling the demand requires weeks of work and usually only the main demand patterns are modelled, such as typical workdays, weekends, and holidays, which means that demand is modelled by and in the resolution defined by the set of demand patterns. Any change in the demand that goes beyond these demand patterns requires the generation of new patterns to ensure that simulation outputs mirror what happens in real life; if demand shifts are frequent, it may become unfeasible to model new demand patterns.
Apparently neither simulation nor ML alone can provide the perfect solution of cheap and fast modelling, cheap and fast adaptation to new contexts, and robust predictions in new and unseen circumstances. Aimsun Live combines simulation and ML for this reason, and ML-based predictions are used to dynamically adjust the demand. But there is still a long way to go. With this in mind, we at Aimsun analyzed how ML models perform in estimating traffic flow in unobservable sections (sections with no real-time observations) given an offline training dataset with data in all sections. And how this model performs when faced with shifts in demand.
We took two real datasets from two cities: Bergen (25 months of data – 2018, 2019 and March 2021), and Wiesbaden (11 months of data – from August 2020 to June 2021). We then extracted demand patterns from these datasets (8 demand patterns in Bergen and 12 demand patterns in Wiesbaden), where each pattern represents 24-hour-long demand in time intervals of 15min, i.e., each pattern represents the demand of a type of day. Finally, we simulated each type of day with normal supply conditions, generating a synthetic dataset of 8 and 12 days, respectively. With this synthetic dataset we trained and tested a ML model using 5-fold cross-validation. This means that for each city, we trained 5 ML models with 80% of the synthetic days and tested each model with the remaining 20% of the days. But the ML model was trained to receive data only from observable sections, those sections with real loop detectors, and to try to estimate traffic flow in unobservable sections. This means that it used data from 110 and 322 sections to estimate the traffic flow in 3732 and 4403 sections, respectively for Bergen and Wiesbaden.
The figure below shows the results of this experiment in terms of %GEH<5 and root mean square error (RMSE). Boxplots represent the 1st and 3rd quantiles, the median (orange), the mean (green triangle) and the 1st and 3rd quantiles minus/plus 1.5 times the interquartile range. In order to prove that the simulated synthetic days are different, and that they represent the most common demand patterns in the real dataset, the boxplots also show the accuracy when the best synthetic day in the training set (the best day of the 80% used for training) is used to predict each of the days in the test set (the remaining 20% of days).
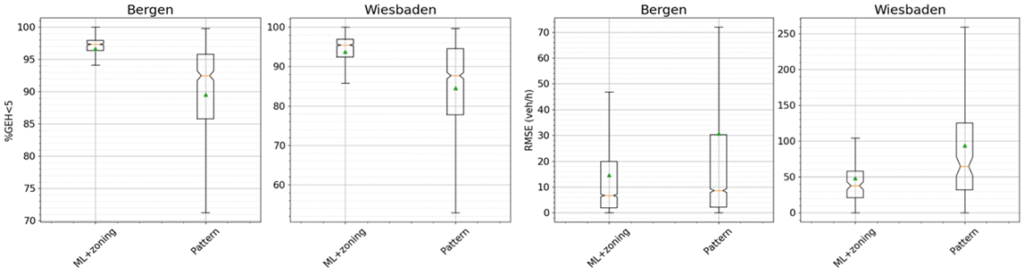
The results show that the ML model effectively modelled the simulated flow in unobservable sections and that the model generalizes incredibly well when faced with new demand patterns.
But which system does a better job of emulating reality? Our next experiment consisted of: (i) training the ML model with the real offline datasets (now including the city of Sydney), (ii) randomly setting sections with loop detectors as observable or unobservable sections, and (iii) testing the model with a new real dataset (with data from September and October 2021). The number of observable and unobservable sections in this experiment were:
- Bergen: 54 observable sections and 34 unobservable sections
- Wiesbaden: 186 observable sections and 81 unobservable sections
- Sydney: 2061 observable sections and 514 unobservable sections
The following figure shows the results of this experiment and compares them with the simulation results using Aimsun Next and the best demand patterns for each day.
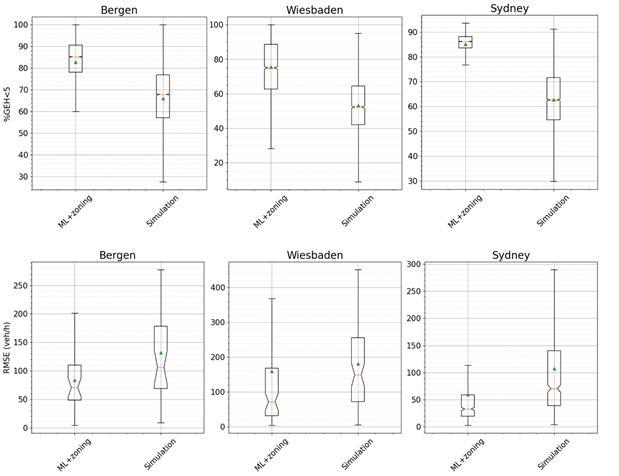
The results show the superior accuracy of the proposed model in making predictions under new traffic demand conditions compared to using the simulation of previous traffic demand patterns.
The conditions of the training and validation sets strengthen this affirmation: the Bergen training set comprises 2018, 2019 and March 2021, so the traffic demand patterns used by the simulation cover 24 months before the COVID-19 outbreak and mobility restrictions, and 1 month under COVID-19 mobility restrictions. However, the validation set mobility context is different as there are no mobility restrictions, the vaccination rate is high, and we can think of it as a middle ground between the pre-COVID period and March 2021.
The Sydney training set comprises the second half of 2020 and August 2021, so the context is one of partial mobility restrictions and severe lockdowns like the one in August 2021. On the other hand, the context for the validation set is one of progressive normalization of mobility. The current state is between the demand patterns of 2020 and those of August 2021.
For Bergen and Sydney, the proposed approach greatly outperforms simulation predictions, meaning that it better fits new demand contexts. Note that traffic simulation systems require accurate modelling of the demand as input; they are also rigid to the input demand unless a dynamic demand adjustment algorithm adjusts the demand to the observed traffic state.
Wiesbaden is different: the training set goes from August 2020 to May to June 2021, but at the end of June 2021, an important bridge located at the southern border of the model was closed. This bridge closure represents a mix of a supply change and demand change because of its border location. Moreover, traffic demand also suffered a small shift related to COVID-19. The approach taken for Wiesbaden achieves overall better accuracy than the simulation, but due to the bridge closure and its impact on the relationships between sections, the variability of the accuracy is greater than in Bergen and Sydney. Indeed, average RMSE is like that obtained by the simulation.
Thus, the results demonstrate the ability of the proposed approach in estimating the flow in unobservable sections and its robustness in front of demand changes. However, the results also glimpse the weakness of the proposed approach, as it is a data-driven approach, in front of supply changes. However, this ability in estimating network-wide flow could be a useful way to enrich or update the initial conditions for simulation. If this is possible, ML can significantly boost simulation-based approaches by improving their accuracy and cost in front of demand shifts. While simulation takes on the burden of predicting traffic under non-recurrent supply changes.

