How to extract patterns from traffic data for better insights into mobility

Ferran Torrent
Senior Data Scientist at Aimsun
Mobility patterns are a cornerstone of mobility demand modelling. The idea is to estimate patterns from mobility observations, such as vehicle counts, and use them to build different demand models that explain or emulate people’s mobility needs. In other words, to understand when, why and how people want to go from A to B, we need to start gathering mobility observations and find patterns.
Back in the days when road traffic data was scarce, mobility patterns were inferred from “field knowledge”, that is, the intuition of the traffic engineer plus the variables that influenced traffic according to the engineer’s experience. In other words, there were a set of variables that described the type of day. For example, the day of the week, the weather, or if it was a holiday. Then, a typical day for each type of day was sampled (usually by manually counting vehicles) and there they had the road traffic patterns for the corresponding city.
The advent of loop detectors and other sensors made it possible to automate road data gathering and provide data for each type of day in order to calculate a pattern that better described all days of the same type. So, if the explanatory variables were weekdays (Monday-Friday) and weekends/holidays, one could take all data for all weekends/holidays, calculate the average or the median or any other reduction metric, and have the pattern for weekends/holidays. The same could be done for all weekdays that were not holidays to get the pattern for workdays.
Basically, this procedure implicitly performs clustering by grouping days according to a set of features, such as day or the week, that according to the engineer’s experience, minimizes both the number of patterns and the traffic flow variance in each group. Then the pattern, or the exemplar, of each group is its centroid according to Euclidean distance if it is calculated using the mean of all of them. This can be generalized to any other method for calculating or choosing an exemplar for each group of days, so we could say that each type of day is a cluster of days, and each pattern is the exemplar that represents each cluster.
Obviously, this methodology can be systemized and automated with a top-down or bottom-up splitting/merging of the types of days. For example, we could start by taking all 14 different types of days (7 days of the week being a holiday or not a holiday, makes 14 types of day) calculate the pattern of each group, merge the most similar pair, and iterate these two steps until we meet a stopping criterion. Alternatively, we could start with a single group with all the days, calculate each pattern and select the sub-group whose pattern differs most from the parent pattern. The first methodology is more efficient, but both should reach similar results with limited explanatory variables, as in this example.
However, is this the right way to define mobility patterns? Clearly not: there is no point in using a set of predefined explanatory variables for grouping days if want to maximize the homogeneity of a set of variables, such as flow, that we already have. In such a case, the right way to extract daily patterns is to cluster days according to the metrics whose homogeneity we want to maximize. For example, if we want to minimize the distance between days according to their daily flow profile, we can use the Euclidean distance of the flow between days. Up for discussion are points like the right distance metric, or which variables to use to calculate the distance, or even how we define patterns or clusters, because these depend on the purpose the patterns.
To illustrate, let’s use the dataset described used in the previous article and sample data from 2018 and 2019, which happen to be the most homogenous sets. We could take the whole dataset, but this would mean that we would have to add year-explanatory variables if we do not use clustering. I regret to say that I cannot share the dataset and I must keep the name of the city anonymous, but you can replicate the following exercise with any dataset that includes loop detector data.
We’ll start by taking the whole dataset and try to group days according to [day-of-the-week and not holidays] and [holidays]. The 2-year dataset has a total of 22 holidays, so there should be enough to have a good pattern if holidays are similar. With this procedure we get 8 groups. For each group we can take the average, or if we think that there may be outliers, we can take the median. Once we have the 8 patterns, we can calculate the distance between them. Since we are doing patterns according to vehicle flow, I will use the GEH<5 as the similarity metric since it is widely used, and it is a relative metric that give values from 0 (lowest similarity) to 100 (highest similarity) so it’s easy for everyone to understand.
The image below shows the GEH<5 for each pair of the 8 patterns. On the left, there are the patterns calculated using the average, and on the right, patterns calculated using the median. According to that, weekdays (Monday-Friday) are very similar, Saturdays and Sundays are different, and holidays are like Sundays. Thus, we could merge weekdays and Sunday-Holidays and have 3 patterns that explain the mobility in the city’s dataset if we prefer to have fewer than 8 patterns.
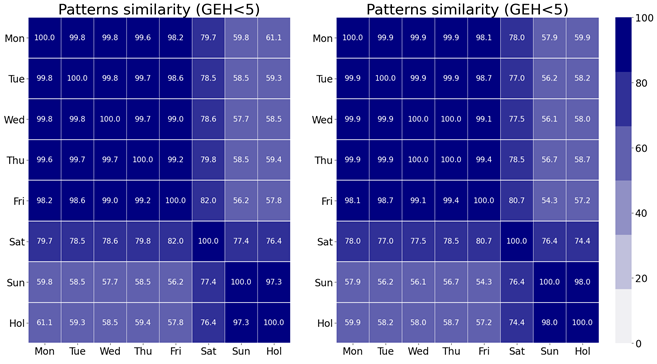
Now we’ll focus on the patterns calculated using the median because their results are slightly better.
If we assume that 8 patterns are fine, we can then compute the GEH<5 of each day with its pattern; this gives us a GEH<5 of 92.31 +/- 4.60 (average +/- standard deviation). Usually, a GEH<5 greater than 85 is sufficient. If we calculate the number of times that our patterns do not reach this value, we get that 4.6% of times or that 1.37% of days have an average GEH<5 lower than 85. These results would indicate that we’ve done ok.
But is this the best we can do? If we cluster daily flow profiles with a hierarchical clustering and take a similarity of GEH<5 between days, with 9 patterns we achieve a performance of 92.61 +/- 3.72 (average +/- standard deviation) and that the GEH<5 is lower than 85 the 3.5% of times (or 0% of days have an average GEH<5 lower than 85!!). In this case, it seems a small improvement, but if we plot the daily GEH<5 for the two methods, we see that in general both approaches give a similar result. However, patterns based on the day of the week suffer a severe drop in performance on a few days. These days correspond to special holidays – January 1st and the drops below 80 correspond to the Christmas holidays.
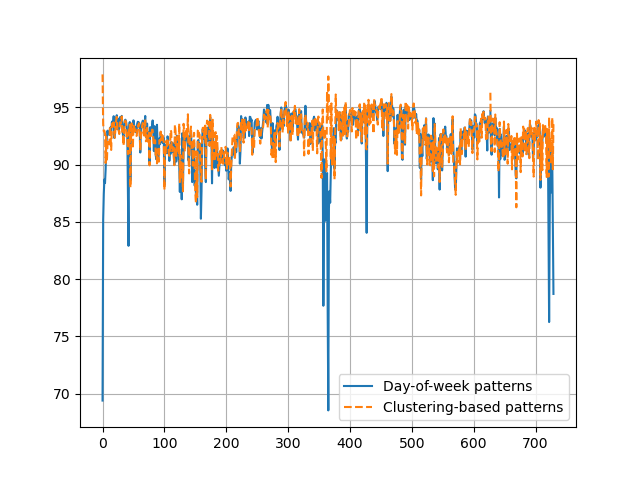
If we look at how clustering-based patterns are organized, we see that January 1st for both years has its own pattern 7. Dec 24th and Dec 31st for both years also have their own pattern 5. Also, a special Sunday, pattern 8, pops up and it also represents Dec 25th and 26th for both years. This pattern 8 is like a typical Sunday, pattern 2, but with even lower flow.
The dataset I used is not a very challenging one as we easily reach a GEH<5 above 90. However, clustering makes it easy to find the patterns that describe the road traffic flow of the dataset, and it can even achieve this without needing to know the dates of holidays or special events, or seasonal mobility drifts (such as over the summer holidays), etc., as this knowledge is implicit in the data.


