Understanding mobility using unsupervised learning

Ferran Torrent
Senior Data Scientist at Aimsun
Unsupervised learning is a great tool for data analysis, particularly for understanding how mobility has changed due to COVID-19. We’ve used a dataset from a real city consisting of traffic flow from 445 loop detectors over a four-year period from January 1st 2017 to May 24th 2021.
Let us say we want to use this dataset to understand if mobility in the last 14 months recovered from the COVID outbreak: we can start by plotting the daily average of the network flow, as in the figure below.
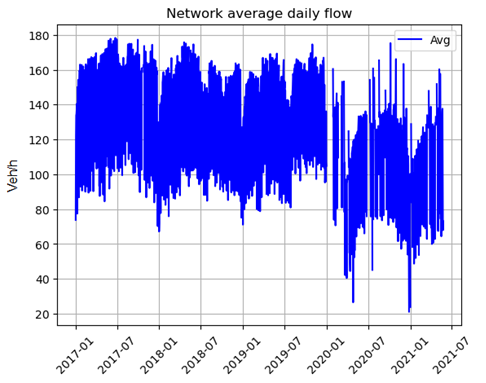
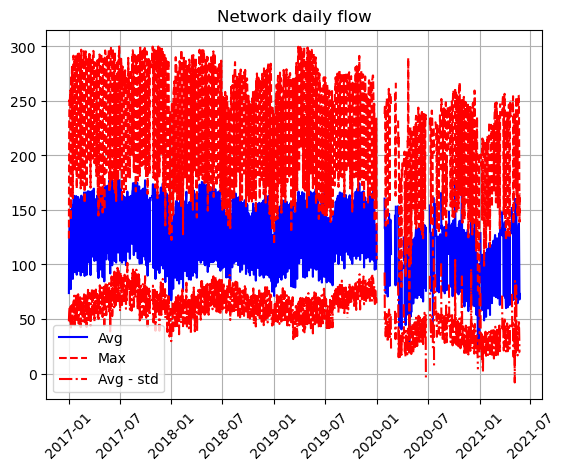
Around March 2020, we can see a drop in flow. Moreover, we see that over the course of 2021, flow has been increasing and is now at Autumn 2020 levels, although still lower than previous years. However, averages can hide important details, so we may decide to not only plot the daily average but the average minus the standard deviation and the maximum daily flow, as in the figure below. It confirms that flow is lower than before March 2020, but the maximum values are closer to pre-COVID than the average.
One of the problems with the previous plots is that the variance of the timeseries and the amount of datapoints lead to plots with solid areas, not curves, from which to visualize the trends. To correct this, we can reduce the number of datapoints by taking the weekly average, standard deviation and maximum, as in the figure below.
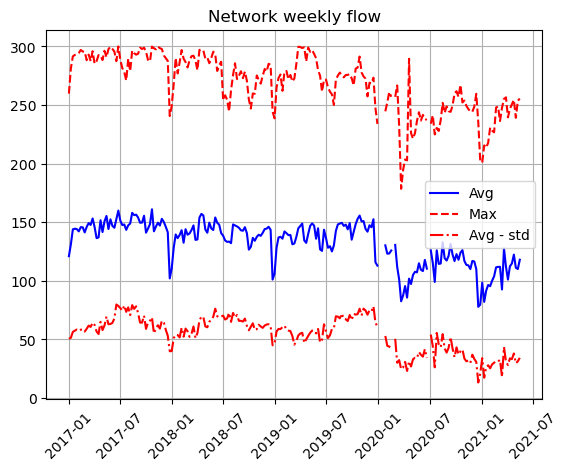
In summary, this analysis shows that despite not knowing if mobility restrictions, working from home, or the closure of economic sectors such as leisure still apply, road traffic has not yet reached pre-March 2020 levels, although it is heading in that direction.
However, we do not know if peak hour is at the same time as before, or if some days of the week are closer to pre-COVID levels than others, so we need to repeat this analysis and take different days of the week or different day-time slices. All these combinations make this easy task quite tedious. Fortunately, machine learning can do the work for us! For example, we can cluster the days of our dataset according to the flow at each detector and throughout the day and see how they are grouped and then calculate the pattern that represents each group, for example, by calculating the centroid (or the exemplar) of each cluster.
Before we go any further, there are some decisions to make: what distance, what clustering algorithm, how many clusters, whether to normalize data or not… Regarding the distance metric, it seems that Euclidean distance is a good choice as we want to see differences in the flow between days throughout the time of day. Another option could be the GEH or the GEH<5 as they are popular metrics to compare traffic flows. Regarding the number of clusters and the clustering method, there are many options. From algorithms that automatically detect the number of clusters from density such as affinity propagation or DBScan, or others that let the user set the number of clusters such as hierarchical clustering or k-means. For this example, we choose agglomerative hierarchical clustering because we want to have control over the number of clusters. We finally decide to not normalize the dataset because we are going to use Euclidean distance over flow only, and we want to keep detectors with high vehicle count more important than the ones with low vehicle count. Once we’ve made these decisions, we just need to run the clustering algorithm and iterate, if necessary, over the number of clusters.
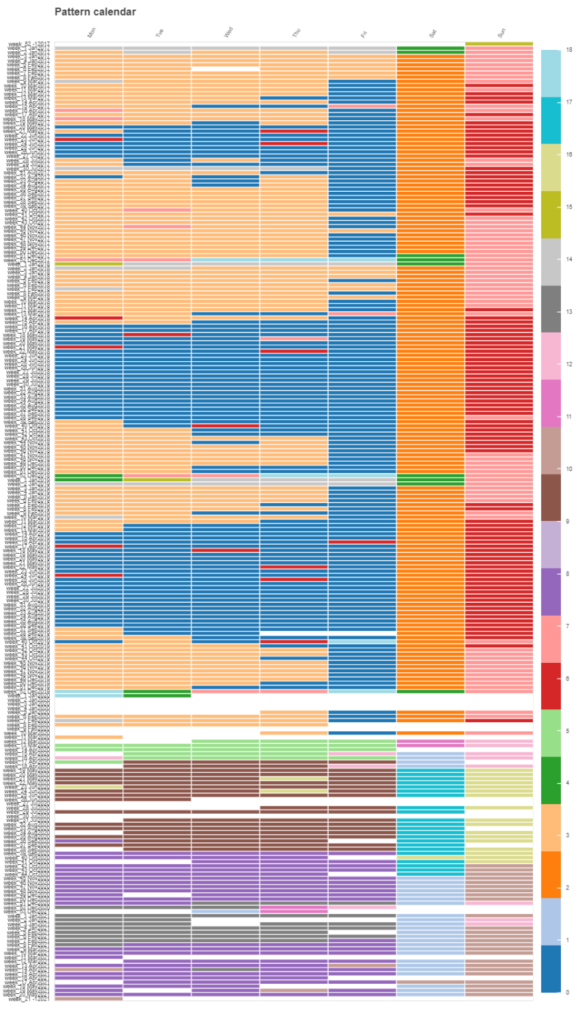
Once the clustering is done, we can visualize pattern distribution over time, for example, using calendar-like table coloring each day-cell according to the pattern of such day as in the next figure. Note that white cells correspond to days without data and the week number, the month and the year are indicated on the legend on the left. The figure show that along three years (2017-2019) workdays are classified in two different patterns or clusters (0 and 3), and that these two patterns alternate each other with the season, but with pattern 0 becoming more mainstream as time goes on. Similarly, 2017-2019 Sundays and holidays are classified between two other patterns (6 and 7) and Saturdays as pattern 2. The beginning of 2020 also fulfills this relation of patterns (at least for the period with data), but suddenly, on March 18th appears a new group of days represented as pattern 5. Afterwards, new patterns pop up which also represent workdays, Saturdays, and Sundays (or holidays). Therefore, we see how none of the patterns before 18th March 2020 happens again, and that none of the patterns after COVID outbreak happened before it. There is a complete change of behavior, and the past did not come back (will it?). Another conclusion is that in the COVID era, there are more patterns, meaning that transport modelers need to do more work to model the demand than in the pre-COVID era, because more patterns involve more demands. But this is a problem for transport modelers, not data scientists, so let us keep it out of the scope of this post.
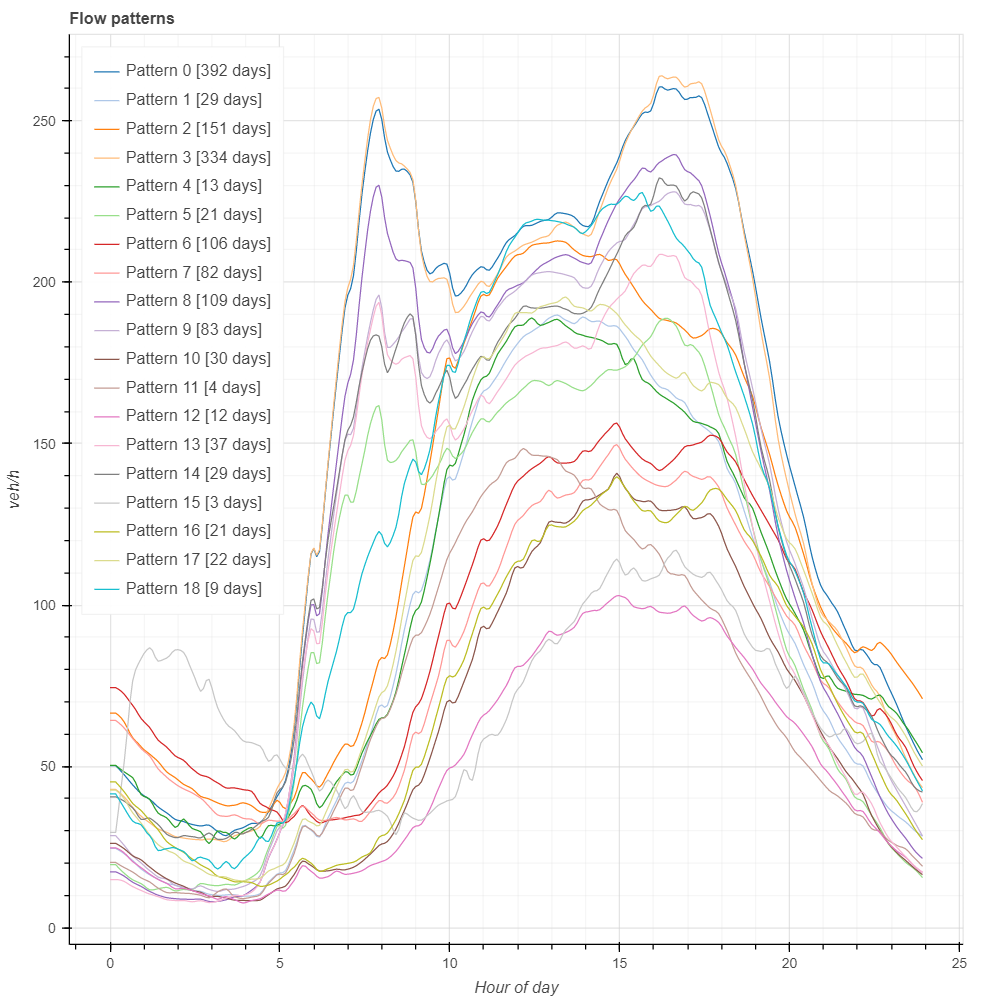
So, clustering has done most of the work for us. We can now just check the patterns representing each cluster and see how far new patterns deviate from the old ones are. The network flow of the centroid of each cluster is showed in the next figure. But there is no point in comparing apples with oranges, or workdays with Sundays.
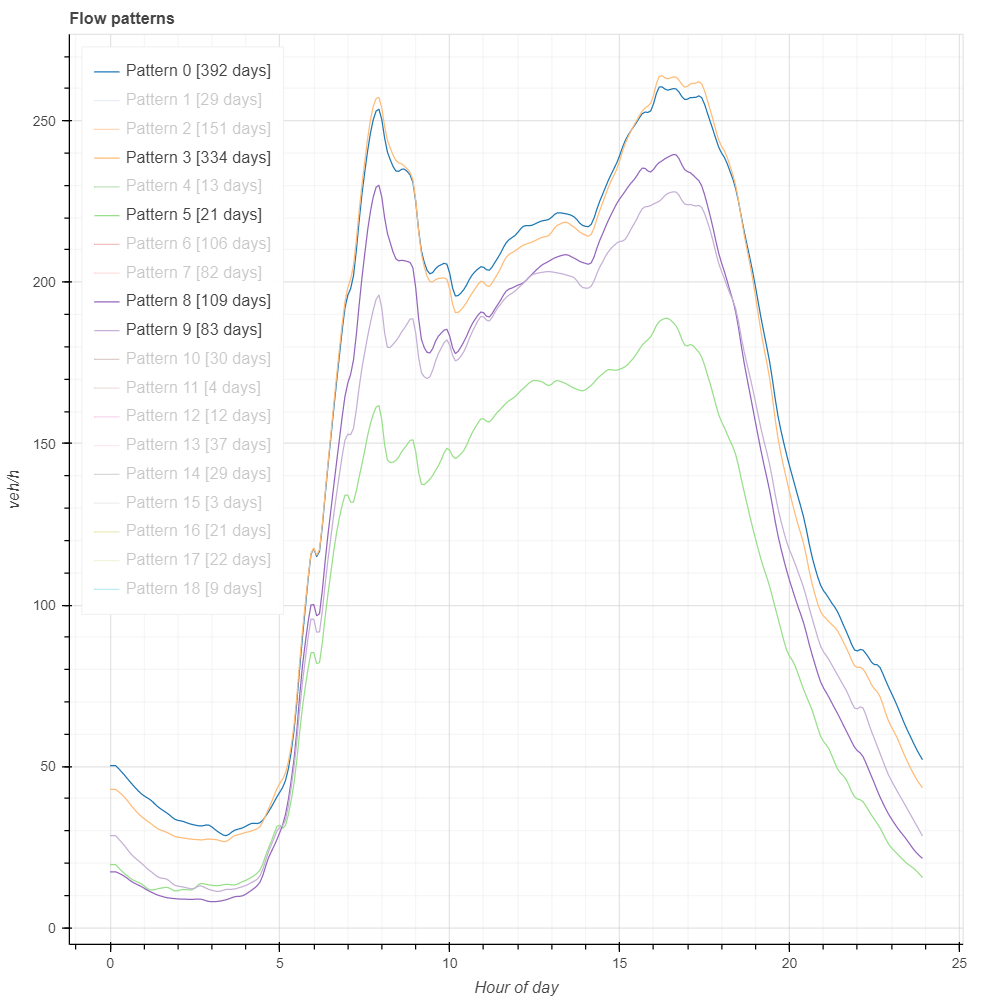
Therefore, we can just plot workdays before (0 and 3) and after COVID (5, 9 and 8 in chronological order) as in the next figure. We see, then, that peak hour flow is increasing and getting closer to the old values, but there has not been significant recovery for early morning and night periods, probable due to curfews, closure of leisure activities, etc.
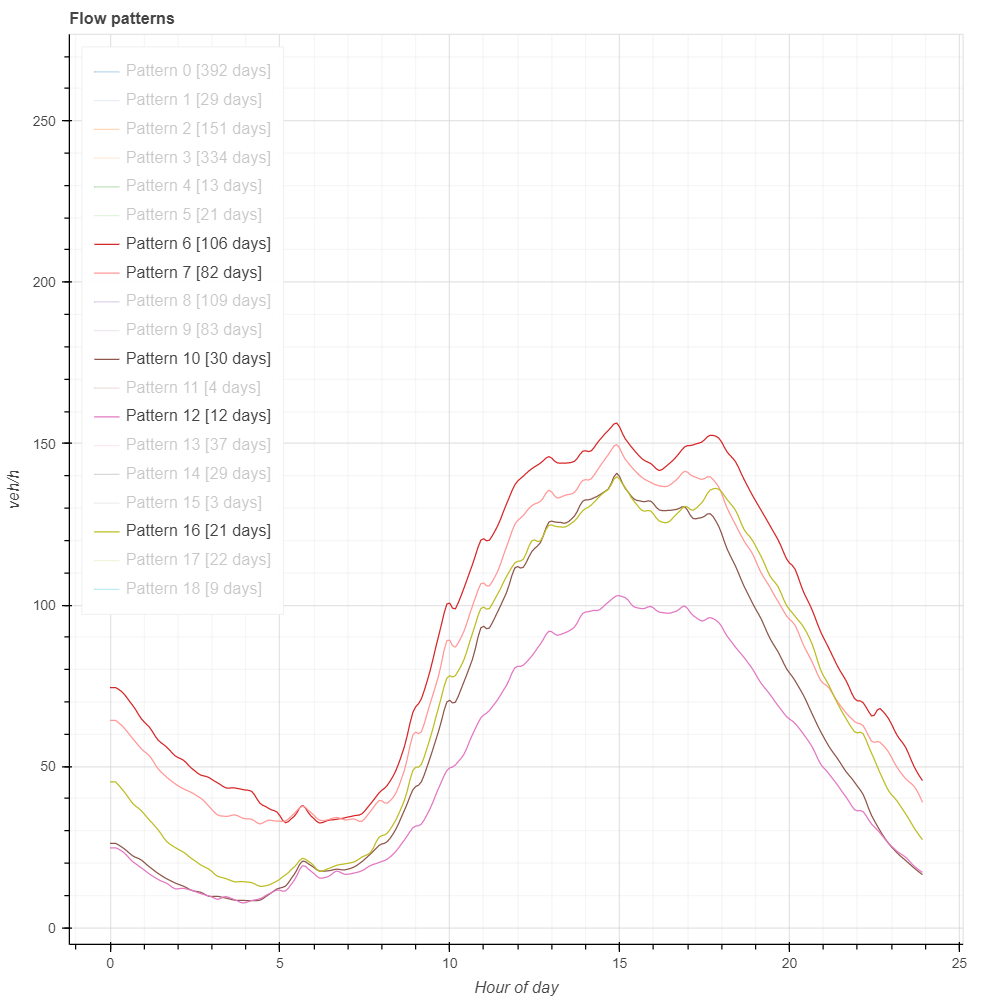
Similarly, COVID Sundays/holidays (12, 16 and 10) and getting closer to pre-COVID Sundays/holidays (7 and 10) during the day, but not for night and early morning. Pattern 16 (Summer 2020) had greater night/morning flow than pattern 10 (2021 Sunday pattern). Thus, it seems that during last Summer, just after controlling the first COVID wave, there was more Sunday night mobility than nowadays.
We can keep doing the same for Saturdays or for other variables such as speed, occupancy, travel time etc., to get an idea of how each one changed and is evolving.
I hope that this post helped to show that unsupervised learning, in general, and clustering in particular, are very useful data analysis tools, and that with them and a few plots we can extract a great deal of insight from a new dataset.
